
Psychologist Paul Ekman spent decades boiling down the fullness of the human feeling to six universal emotions. He then developed a method to identify micro-expressions of the face and map them on to corresponding emotions. Some of his theories ended up seeping into other areas of live, most famously influencing the training of Behavior Detection Officers who scanned the faces of incoming passengers for signs of deception at U.S. airports. Unsurprisingly, the theory and is applications not only drew criticisms, they also showed disturbing flaws. Facial expressions, his critics argue, are not innate, they depend on context, culture and experience.
Ekman has since modified his theory (albeit not drastically) but his idea of an universality of emotions has nevertheless been adopted by some tech companies to train algorithms aimed at detecting emotions from facial expressions. Experts studying the science of emotion are concerned that these algorithms, now used to assess mental health, employability, deceit and other key determinants of our lives, make critical decisions about our lives based on problematic science.

Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti

FERET Dataset, 1993, 1996, National Institute of Standards, Dataset funded by the United States military’s Counterdrug Technology Program for use in facial recognition research

Takeo Kanade, Jeffrey F. Cohn, Yung-Li Tian, Cohn-Kanade AU-Coded Expression Database, 2000. Courtesy Fondazione Prada
I discovered the work of Ekman and his critics in Training Humans, an exhibition conceived by AI researcher Kate Crawford and artist and researcher Trevor Paglen for the Fondazione Prada in Milan. The show charts and examines the photos and systems used by scientists since the 1960s to teach AI systems how to “see” and categorise human beings.
Training Humans explores how we are represented and codified through training datasets, and how technological systems harvest, label and use this material. Often with biases and weaknesses that become more visible as these classifications gain ground and influence. Within computer vision and AI systems, forms of measurement turn into moral judgments. Could these judgements in turn influence our own behaviour, our vision of the world and the individuals who inhabit it?

Li Fei-Fei, Kai Li, Image-net, 2009 (detail) Courtesy Fondazione Prada
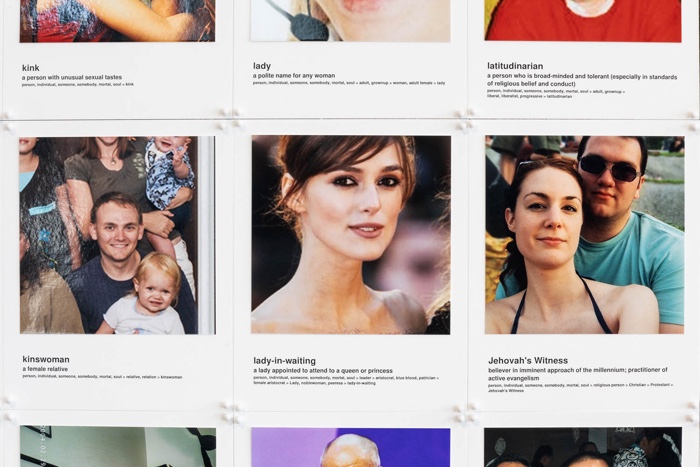
Li Fei-Fei, Kai Li, Image-net, 2009 (detail) Courtesy Fondazione Prada
ImageNet is perhaps the biggest surprise of the exhibition. You expected earlier systems presented in the show to come with their fair share of failings. But ImageNet was launched in 2009 by researchers at Stanford and Princeton universities so it comes with a certain credibility. This visual database counts more than fourteen million images and is one of the most widely used sources for training AI technologies to recognise people and objects. The photos have been classified and annotated by workers on Amazon Mechanical Turk, making ImageNet one of the world’s largest academic user of Mechanical Turk. However, the prejudices of the human Turkers found their way into ImageNet and as ImageNet Roulette, an application developed by Paglen and Crawford, demonstrates, the prejudices of that labour pool is echoed in the AI technologies that rely on that data.

Trevor Paglen Studio, ImageNet Roulette, 2019. Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti
ImageNet Roulette uses an algorithm trained on portraits found on ImageNet, it detects human faces in any uploaded photo and assigns them labels, using one of ImageNet’s 2,833 subcategories of people. The project went viral when people tested it on their own selfies and found out that the result of the face recognition process were ranging from utterly idiotic to downright racist or sexist. I tried the project while visiting the exhibition. ImageNet Roulette was incredibly fast at labelling me an oboist, an aviatrix and even an “alkie”. The labels changing depending on whether or not i had my headphones on or if i allowed my hair to go all Dave.

Li Fei-Fei, Kai Li, Image-net, 2009. Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti
The exhibition makes it easy to understand where the flaws in the face recognition system come from. Right before the a ImageNet Roulette installation, visitors encounter walls plastered with annotated photos from ImageNet. A guy happily dancing in a crowd with an arm raised is labelled a “gouger. An attacker who gouges out the antagonist’s eye”; an man with a beard and a rounded skullcap protesting in the street is tagged “anti-American”; white, potbellied middle aged men are “board members”, etc. It pleased me no end however to see a photo of Donald Trump with the label “mortal enemy”.
Since AI is increasingly used by tech companies, university labs, governments and law enforcement agencies, its inherent biases can have a tragic impact on the lives of individuals whose face ends up being inserted in the data sets, after having been categorised and labelled using parameters we know little of.
ImageNet Roulette quickly went viral. Five days after its launch, ImageNet announced it would remove remove 438 people categories and 600,040 associated images from its system.
The rest of the exhibition is equally fascinating. There isn’t any other artwork but there is an impressive documentation of projects that have, at some point, attempted to catalog and reduce our bodies and behaviours to a series of labels. There are mugshots and fingerprints of course but also hand gestures, voice samples that attempt to categorise local accents, irises, gait, etc. It feels like pretty much anything about us can be dissected and measured. Yet, the conclusion that emerges is that there exists no universal, no neutral idea of what/who we are. The image we have of ourselves never corresponds to the one others have of us. It doesn’t even correspond to the image we had of ourselves 5 years ago. It certainly never corresponds to the one machines reduce us to. Humans are simply too complex for machines. At least, that’s what we like to think.
Kate Crawford and Trevor Paglen commenting on Training Humans

Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti

Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti

Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti

Left: Yilong Yin, Lili Liu, Xiwei Sun, Sdumla-Hmt, 2011. Right: Woodrow Wildon Bledsoe, A Facial Recognition Project Report, 1963. Courtesy Fondazione Prada. Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti

Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti

On the wall: Bor-Chun Chen, Chu-Song Chen, Winston H.Hsu, Cross-Age Celebrity Dataset (CACD), 2014 and on the screens: Gary B.Huang, Manu Ramesh, Tamara Berg, Erik Learned-Miller, Labelled Faces in the Wild, 2007. Training Humans at Osservatorio Fondazione Prada. Photo Marco Cappelletti

CAISA Gate and Cumulative Foot Pressure, 2001, Shuai Zheng, Kaigi Huang, Tieniu Tan and Dacheng Tao Created at the Center for Biometrics and Security Research at the Chinese Academy of Sciences, the dataset is designed for research into recognizing people by the signature of their gait
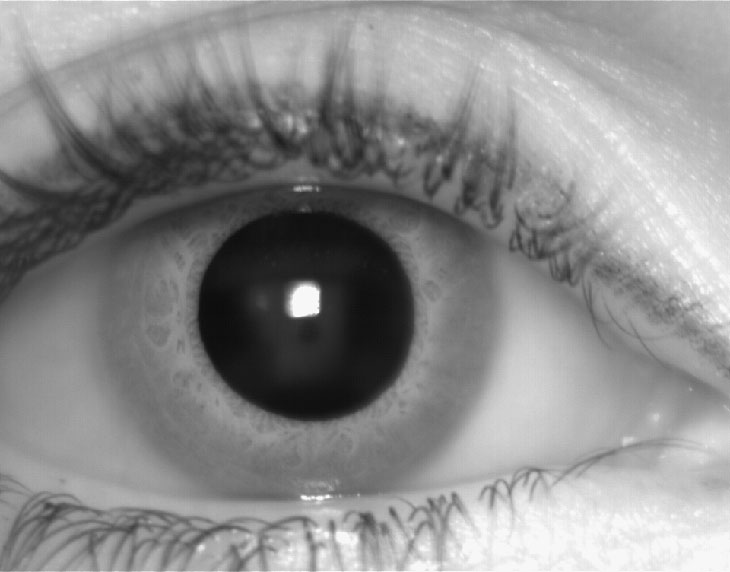
SDUMLA, HMT, 2011, Yilong Yin, Lili Liu, and Xiwei Sun, The finger and iris prints come from a larger multimodal dataset developed at Shandong University in Jinan, China which includes faces, irises, finger veins, and fingerprints for use in biometric applications
Paglen and Crawford have taken ImageNet Roulette offline on 27 September, as it had triggered the kind of public debate about the politics of training data the duo was hoping for. If you still want to try it, you’ll have to go to Milan.
Training Humans is at the Osservatorio Fondazione Prada in Milan until 24 February 2020.